Blog
- Serhiy Ryabukhin, Dmytro Volochnyuk
- 33209
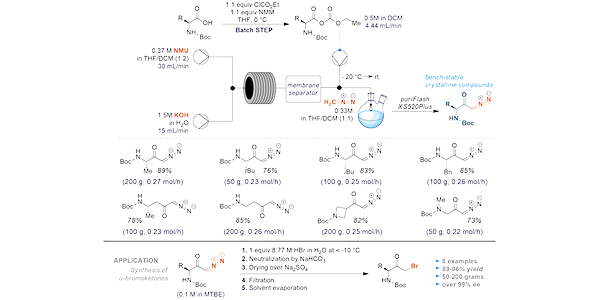
Formulation scale-up is a significant challenge in drug development. Often, the initial research and development phases focus on optimizing the formulation at a milligram scale without fully addressing the complexities associated with scaling up for large-scale production. This oversight can lead to difficulty connected with transitioning from lab-scale to commercial manufacturing.
By focusing on this problem, Enamine chemists can effectively address the challenges of scaling up synthetic processes in cost-effective manner, leading to more successful transitions from lab-scale to commercial production.
- Pavel Mykhailiuk
- 36377
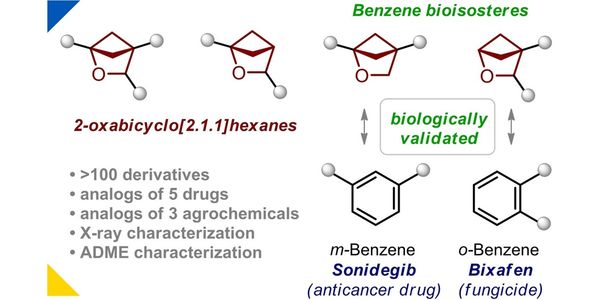
- 2-Oxabicyclo[2.1.1]hexanes: synthesis, properties and validation as bioisosteres of ortho- and meta-Benzenes
- Spiro[3.3]heptane as a Saturated Benzene Bioisostere
- Light-enabled scalable synthesis of bicyclo[1.1.1]pentane halides and their functionalizations
- 2-Oxabicyclo[2.2.2]octane as a new bioisostere of the phenyl ring
- 1-Azaspiro[3.3]heptane as a Bioisostere of Piperidine
- Oleksandr Grygorenko
- 40520

Amino acids, including unnatural derivatives, play a pivotal role in medicinal chemistry due to their ability to modulate the properties of peptides and serve as versatile building blocks for drug design. Their intrinsic combination of amino and carboxylic functional groups makes them highly valuable in therapeutic development. At Enamine, over 20 years of research have been devoted to this field, with a focus on synthetic strategies such as conformational restriction, fluorination, and isosteric replacements. These modifications enhance the functionality and stability of peptides and small molecules, providing innovative solutions for drug discovery. Here we highlight examples of amino acids synthesized at Enamine and their successful integration into drug candidates, showcasing their potential to drive advancements in medicinal chemistry.
- Oleg Luferenko
- 31045

Since our trial release of the new EnamineStore last year we’ve been hard at work moving the rest of the functionality to the new web store and listening to the feedback we’ve received from our users. Even though we still have things to catch up on and review we think our application is ready to welcome all of our user base.
- Andrii Buvailo
- 28919

Solute carriers (SLCs) have often been overshadowed by more prominent protein families in drug discovery, such as kinases and G protein-coupled receptors. However, SLC proteins hold significant therapeutic potential due to their role in various diseases. Among them, the high-affinity norepinephrine transporter (NET/SLC6A2) has received considerable attention, but the limited chemical diversity of known ligands presents a challenge for identifying novel compounds. The new article published in Journal of Chemical Information and Modeling explores a computational screening pipeline developed to discover new NET inhibitors, utilizing a data-driven approach to expand known chemical space and optimize target selection.
- Enamine Communications
- 28820

Preparation of the screening libraries from the stock in dry powders always takes extra time and, in many cases is uneconomical due to compound waste.
Enamine’s Liquid Stock collection backed with our state-of-the-art compound management provides time- and cost-effective solution for design of the bespoke libraries easily customizable in terms of both composition and format. This collection currently consists of more than 296,000 compounds stored as 10 mM DMSO solutions available for cherry-picking.
- Ivan Kondratov
- 32569
No doubt Fluorine is an extremely important element for Medicinal chemistry. There are tons of reviews with numerous examples of cases when the introduction of Fluorine or fluorinated groups led to the improvement of activity, selectivity, ADME-properties of the molecules therefore every year we commonly see many fluorinated molecules among FDA-approved drugs.
- Enamine Communications
- 28089

Dear Customers, Dear Colleagues, Dear Friends.
This morning, russia carried out another act of aggression, firing dozens of rockets at peaceful cities in Ukraine, including Kyiv. Another act of barbarian terrorism. Despite it, we stand firm and resilient.
- Ivan Kondratov
- 30687
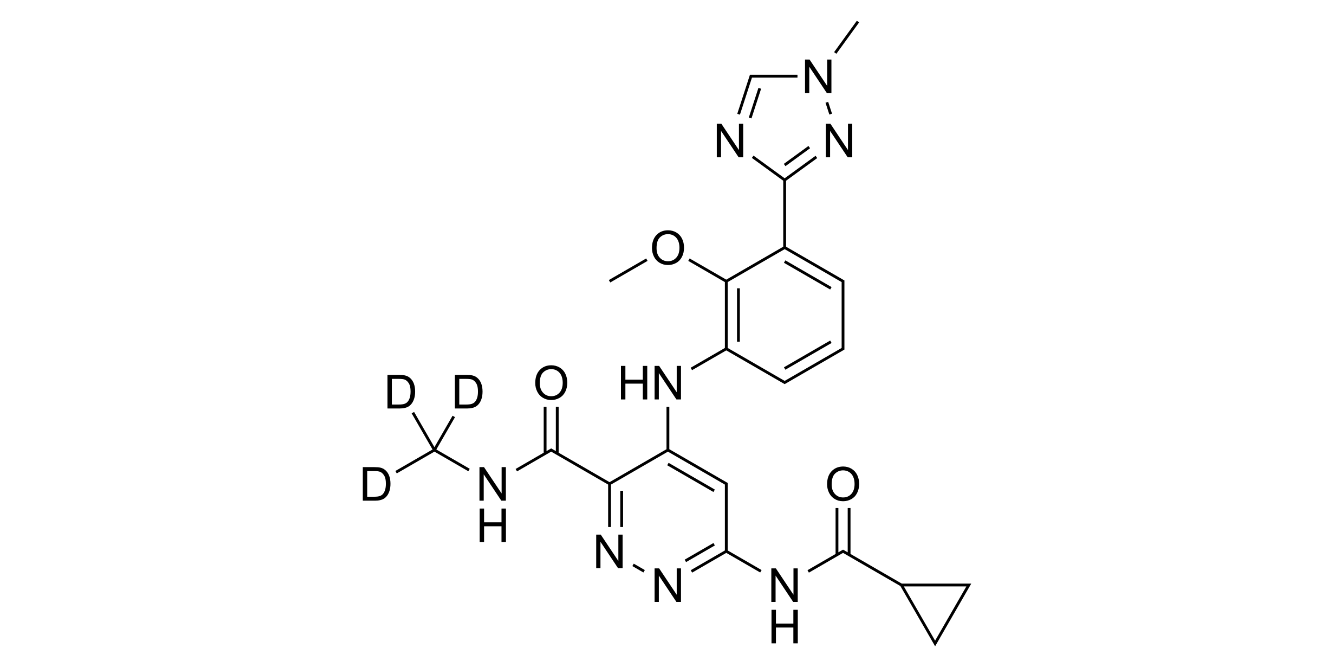
A week ago, FDA-approved TYK2 inhibitor deucravacitinib (trade name Sotyktu) for moderate-to-severe plaque psoriasis and there are several reasons which make the news remarkable.
- Ivan Kondratov
- 30710
Last week there was news that is remarkable for the Ukrainian chemical community. Kyiv administration agreed on the renaming of Murmanska street. Now this street will be named after Academician Valery Kukhar.
Such a renaming is a part of the huge campaign in Kyiv and other Ukrainian cities aiming to remove the names of Russian-related names of streets, squares and other objects and give them actual names.
- Andrii Buvailo
- 38265

The interest of pharmaceutical companies in DNA-encoded chemical libraries (DEL) technology has been growing over the years, with numerous organizations now having their own screening programs using DELs, or outsourcing capabilities from specialized DEL providers.
- Enamine Charity Fund
- 27773

The Enamine Charity Fund is dedicated to helping people in need and also to helping students get back to safe studying during the time of war in Ukraine.
- Ivan Kondratov
- 29632
There are not so much info in the media about this story however I suppose it is remarkable. And while it is not completely my topic, I suppose it is worth sharing, because it obviously demonstrates how innovative products of biotech can help Ukraine today.
- Oleg Luferenko
- 28848
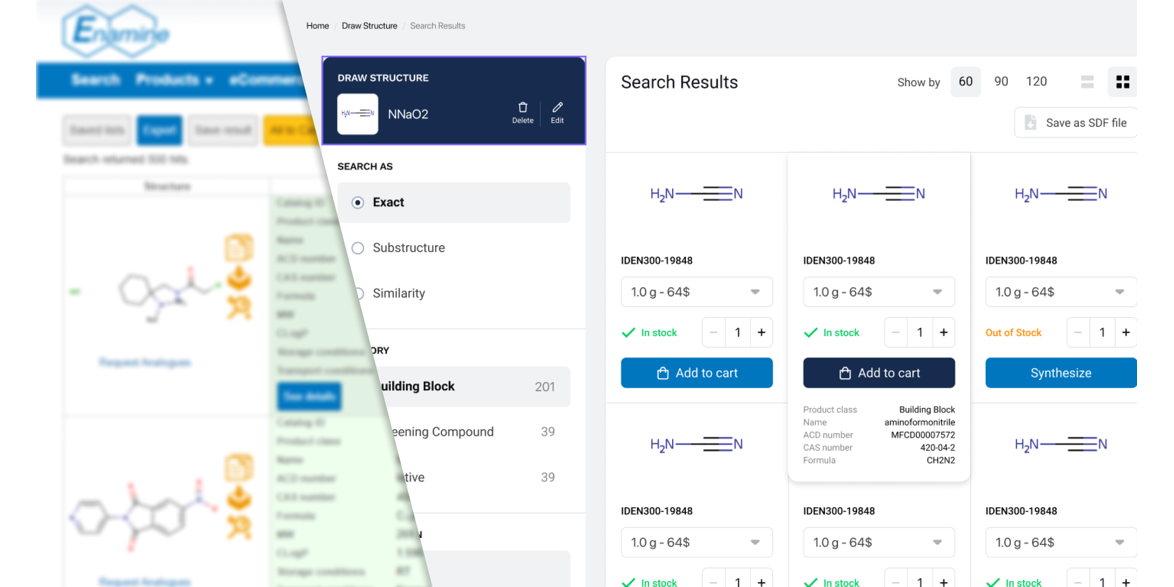
Time for the Enamine Store update
We are excited to announce that despite all the difficulties we faced with the Russian Invasion of Ukraine we are launching an all-new user interface for our web store.
Our team has been working tirelessly to upgrade our enaminestore.com over the past year. We believe that our reimagined design will help you enjoy your experience and make our services easier to use.
- Ivan Kondratov
- 30514
Few weeks ago a new biotech appeared on the map: Vicinitas Therapeutics launched with $65 Million in Series A. The company is focused on developing small-molecule drugs that stop the degradation of specific proteins to restore their levels for therapeutic benefit. The main value and basis of the biotech is the research of Daniel Nomura’s lab at UC Berkeley on so-called Deubiquitinase-targeting chimeras (or DUBTACs) for targeted protein stabilization.
- Enamine Communications
- 29336

Dear Colleagues, Customers, and Friends,
More than four months from the beginning of the full-scale Russian invasion and it is not clear when it will be over. The world is getting used to the Russian-Ukrainian war. At the same time, I suppose Ukraine should not exit from the focus of the whole world while Russia continues its aggression.
- Andrii Buvailo
- 34135

Proteins are essential components of living matter – they function as building blocks for cells and tissues, as well as participate in signaling and practically all biochemical activities. However, each protein operates correctly only for a limited amount of time and is eliminated by molecular machinery after it has reached its “functional shelflife”. To maintain a healthy and functional proteome, cells tightly control protein turnover processes, ensuring that misfolded, damaged, and old proteins exit the game in a timely manner. This sophisticated mechanism of degradation was recently hijacked by the drug discovery industry to develop new small molecule therapies — protein degraders.
- Ivan Kondratov
- 30602

Because of the war I’ve missed the news about the death of Sidney Altman on April 5, 2022. Altman is outstanding researcher, who first discovered the catalytical properties of RNA. He shared the Nobel prize in Chemisry with Thomas Cech in 1989. Their research results seem even more important nowadays when RNA-targeted drugs becomes reality.
- Ivan Kondratov
- 5732
Three months of the full-scale ruzzian invasion are over however it’s still really heartwarming for as at Enamine to get more and more words and signs of support from our customers and partners. The recent example is our joint letter to Science journal initiated by our friends from UCSF John J. Irwin and Brian K. Shoichet.
- Enamine Communications
- 4487
We are glad to inform you that we have fully restored the scope of our building block catalog as it was before the 24th of February war outbreak. The catalog lists over 238,000 off-the-shelf products. Such items are again offered in the various batch sizes reaching up to 100 grams in many cases to give you full scale of choice for your projects. Please visit https://enaminestore.com/catalog to make structure searches and order online.